
Gyeongrok Oh
PhD Student, Korea University
I am a Ph.D. student in the Department of Artificial Intelligence at Korea University, where I am advised by Prof. Sangpil Kim. I previously served as a visiting researcher at Samsung Advanced Institute of Technology (SAIT), collaborating with the Computer Vision Lab.
My research aims to build robust perception and reasoning systems for embodied intelligence, drawing on computer vision, multi-modal learning, and generative models to understand dynamic 3D environments.
News
- Sep. 2025 One paper on vision-language navigation was accepted to NeurIPS 2025.
- May 2025 One paper on vision-language navigation was accepted to ICML 2025.
- Feb. 2025 One paper on occupancy prediction was accepted to CVPR 2025.
- Jul. 2024 One paper on text-to-video generation was accepted to ECCV 2024.
Research
* indicates equal contribution.
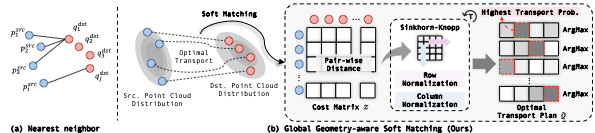
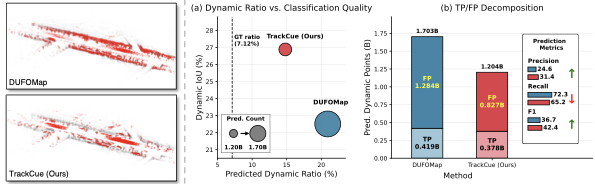
Training-Free Global Geometric Association for 4D LiDAR Panoptic Segmentation
Pre-print, 2025.
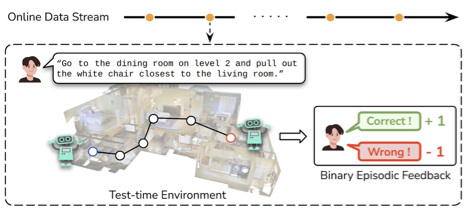
Test-Time Adaptation for Online Vision-Language Navigation with Feedback-based Reinforcement Learning
ICML, 2025.

All Publications
Motion Cues from Image-based Point Tracking for LiDAR Scene Flow Estimation
Youngdong Jang*, Gyeongrok Oh*, Jong Wook Kim, Hyunju Ryu, Hyung-gun Chi, SeungHyeon Kim, Seungryong Kim, Jonghyun Choi, Sangpil Kim
Pre-print, 2026.
Training-Free Global Geometric Association for 4D LiDAR Panoptic Segmentation
Gyeongrok Oh, Youngdong Jang, Jonghyun Choi, Suk-Ju Kang, Guang Lin, Sangpil Kim
Pre-print, 2025.
LVMark: Robust Watermark for Latent Video Diffusion Models
MinHyuk Jang*, Youngdong Jang*, JaeHyeok Lee, Feng Yang, Gyeongrok Oh, Jongheon Jeong, Sangpil Kim
IEEE Transactions on Information Forensics & Security, 2026.
Active Test-time Vision-Language Navigation
Heeju Ko, Sungjune Kim, Gyeongrok Oh, Jeongyoon Yoon, Honglak Lee, Sujin Jang, Seungryong Kim, Sangpil Kim
NeurIPS, 2025.
Test-Time Adaptation for Online Vision-Language Navigation with Feedback-based Reinforcement Learning
Sungjune Kim*, Gyeongrok Oh*, Heeju Ko, Daehyun Ji, Dongwook Lee, Byung-Jun Lee, Sujin Jang, Sangpil Kim
ICML, 2025.
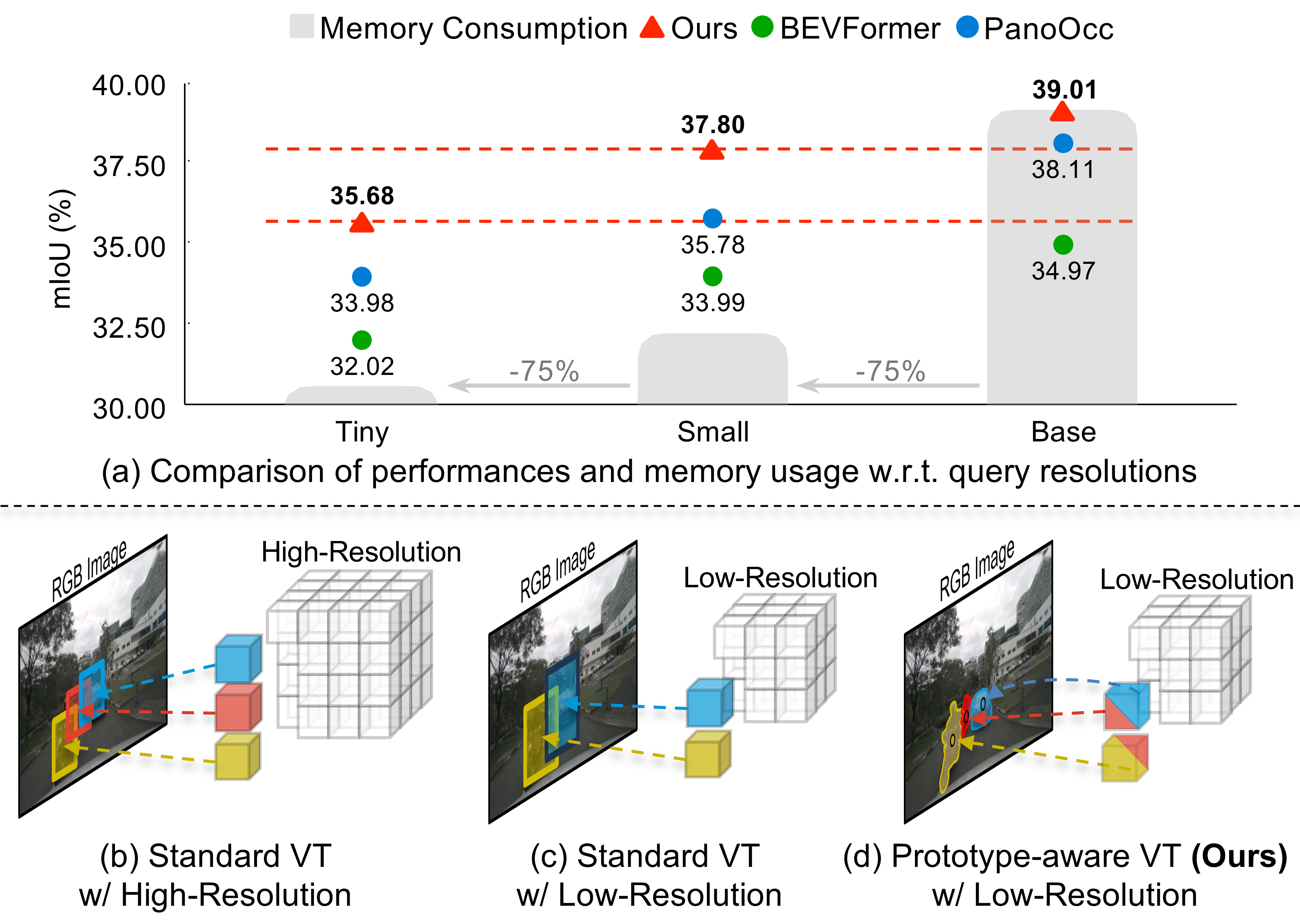
3D Occupancy Prediction with Low-Resolution Queries via Prototype-aware View Transformation
Gyeongrok Oh*, Sungjune Kim*, Heeju Ko, Hyung-gun Chi, Jinkyu Kim, Dongwook Lee, Daehyun Ji, Sungjoon Choi, Sujin Jang, Sangpil Kim
CVPR, 2025.
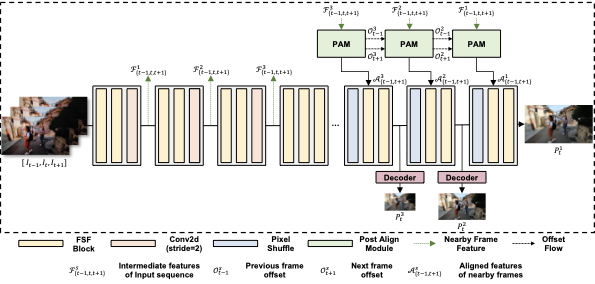
FPANet: Frequency-based Video Demoireing using Frame-level Post Alignment
Gyeongrok Oh, Sungjune Kim, Heon Gu, Sang Ho Yoon, Jinkyu Kim*, Sangpil Kim*
Neural Networks, 2024.
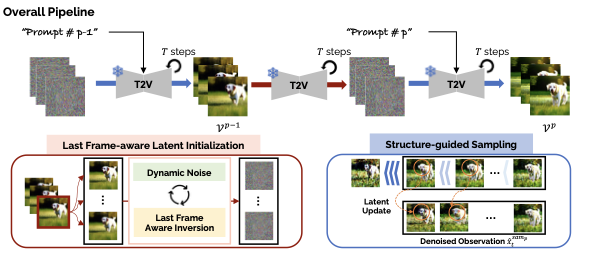
MEVG: Multi-event Video Generation with Text-to-Video Models
Gyeongrok Oh, Jaehwan Jeong, Sieun Kim, Wonmin Byeon, Jinkyu Kim, Sungwoong Kim, Sangpil Kim
ECCV, 2024.
Robust Sound-Guided Image Manipulation
Seunghyun Lee*, Hyung-gun Chi*, Gyeongrok Oh, Wonmin Byeon, Sang Ho Yoon, Hyunje Park, Wonjun Cho, Jinkyu Kim, Sangpil Kim
Neural Networks, 2024.
Audio-Guided Implicit Neural Representation for Local Image Stylization
Seung Hyun Lee*, Sieun Kim*, Wonmin Byeon, Gyeongrok Oh, Sumin In, Hyeongcheol Park, Sang Ho Yoon, Sung-hee Hong, Jinkyu Kim, and Sangpil Kim
Computational Visual Media, 2024.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-based 3D Object Detection
Gyusam Chang*, Wonseok Roh*, Sujin Jang, Dongwook Lee, Daehyun Ji, Gyeongrok Oh, Jinsun Park, Jinkyu Kim, Sangpil Kim
AAAI, 2024.
Functional Hand Type Prior for 3D Hand Pose Estimation and Action Recognition from Egocentric View Monocular Videos
Wonseok Roh, Seung Hyun Lee, Wonjeong Ryoo, Gyeongrok Oh, Soo Yeon Hwang, Hyung-gun Chi, Sangpil Kim
BMVC (Oral), 2023.
Sound-Guided Semantic Video Generation
Seunghyun Lee, Gyeongrok Oh, Wonmin Byeon, Wonjeong Ryoo, Sang Ho Yoon, Jinkyu Kim*, Sangpil Kim*
ECCV, 2022.